
There has been a lot of activity over the last 18 months regarding SDN and similar technologies disrupting the traditional network architecture stack.
Today we have vendors such as BigSwitch Networks disrupting the traditional network vendors by allowing customers to purchase whitebox network hardware and use their SDN controller to manage the network. Microsoft with their 2016 server release will have built in a network controller role which can be installed plus support for VXLAN and NVGRE which is leveraging the same technology stack Microsoft uses in their Azure cloud services.
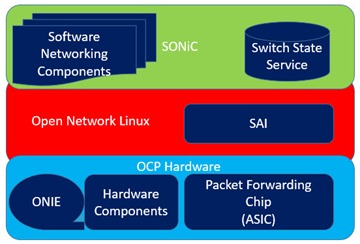
Microsoft also just recently announced a fully open sourced “Software for Open Networking in the Cloud (SONiC)’ for running network devices like switches, built in collaboration with leading networking industry vendors Arista, Broadcom, Dell, BigSwitch and Mellanox.
Vendors such as Cisco are playing catch up with ACI which has been known to cause instability within customer environments. There is no question these events are creating doubt within customers’ minds as to whether SDN really is ready for prime time. I seem to recall certain vendors creating the same doubt in customers’ minds about cloud technologies around 4 years ago.
There is a good industry overview from Brad Casemore Research Director, Datacenter Networks @ IDC available from BigSwitch Networks which I’d recommend you take a look at.
If you are looking at performing a technology refresh regarding your network infrastructure, you would be crazy these days to not consider some sort of SDN technology working within your environment within the next 2-3 years. Hybrid cloud is the way customers are wanting to consume cloud services in the short to medium term and the only way to facilitate network connectivity in a consistent, easy to manage and rapid deployment method is by using SDN in a manner which allows openness and customer choice.





